
사람 얼굴을 탐지하는 모델을 만들기 위해 여러 데이터셋들을 찾고 있었는데, 거의 대부분 서양인으로 기반으로 한 데이터셋들이 많았다.
게다가 한국인을 대상으로 한 데이터셋들은 개인 정보다 뭐다 해서 거의 찾아볼 수가 없었다.
우연히 AI HUB라는 국내 사이트를 찾게 되었는데, 생각보다 유용한 데이터셋들이 엄청 많았다. 구글에 ai-허브라고 치면 성인인증이 뜬다
모두 국내에서 주관한 데이터셋이기 때문에 한국인, 국내 장소 등등 구하기 쉽지 않은 데이터셋들이다.
물론 AI-HUB에 있는 모든 데이터셋들은 인공지능 학습모델의 학습용으로만 사용할 수 있으며, 다른 행위에 대해서는 일절 허락되지 않음.
https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=82
AI-Hub
※ 내국인만 데이터 신청이 가능합니다. 목록 데이터 개요 데이터 변경이력 데이터 변경이력 버전 일자 변경내용 비고 1.1 2022-01-18 데이터 품질 보완 1.0 2021-06-18 데이터 최초 개방 데이터 히스토
aihub.or.kr
위 한국인 감정인식 데이터셋을 예시로 들면,
원천 데이터 약 500,000개 이미지. 7개의 감정 범주 (기쁨, 당황, 분노, 불안, 상처, 슬픔, 중립)과 성별, 나이대 등등 구성된다.
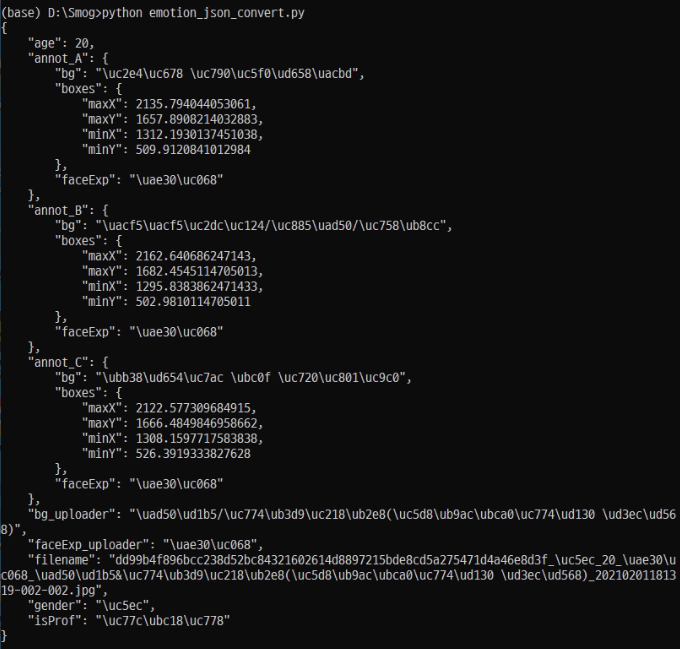
레이블 내 나이, 성별, 얼굴 좌표가 포함되어 있음.
레이블 파일 내부 좌표 접근:
for구문 - for구문 - age, gender, annot_A, annot_B, annot_C
얼굴 좌표 annot이 총 3개(A, B, C)가 있는데, 직접 확인해본 결과 모두 얼굴 좌표이긴 하지만 약간씩 좌표가 다르며 장소 레이블이 다르다.
장소를 세세히 설명하기 위한 것으로 보이며, 만약 얼굴 좌표가 필요하다면 annot_A 하나만 써도 될 듯하다. 그렇다면 break 구문적용 할 것.
얼굴 좌표는 max X, Y와 min X, Y로 설정되어있어서 통합 데이터셋을 만들때는 변환 작업이 필요하다.
그래서 나는 얼굴 좌표가 어떻게 설정되어 있는지 확인해보려고 OpenCV Rectangle을 사용하여 출력하는 코드를 작성해보았다.
import cv2
import json
import numpy as np
# JSON 레이블 파일 경로
json_path = 'D:/감정인식 복합 영상/한국인 감정인식을 위한 복합 영상/' \
'Validation/[라벨]EMOIMG_기쁨_VALID/img_emotion_validation_data(기쁨).json'
# 이미지 데이터셋 경로
image_path = 'D:/감정인식 복합 영상/한국인 감정인식을 위한 복합 영상/' \
'Validation/[원천]EMOIMG_기쁨_VALID/'
count = 0
# 레이블에 한글이 포함되어 있으므로 UTF-8로 인코딩
with open(json_path, 'r', encoding='UTF-8') as jf:
json_data = json.load(jf)
# JSON 레이블 데이터 내부 탐색 시작
for i in json_data:
# print(json.dumps(i, indent=4, sort_keys=True))
# break
# 하나의 이미지 파일마다 가지고 있는 데이터 값들을 확인하는 작업
for x in i:
# 파일 명, 나이, 감정 데이터 값을 할당
filename, age, emotion = i['filename'], i['age'], i['faceExp_uploader']
# 3개의 서로 다르게 분류된 장소 데이터 값
annot_A, annot_B, annot_C = i['annot_A'], i['annot_B'], i['annot_C']
# 이미지 파일 명이 한글이므로 OpenCV는 한글 지원 안되므로 numpy를 사용해 불러옴
n = np.fromfile(f'{image_path}/{filename}', np.uint8)
img = cv2.imdecode(n, cv2.IMREAD_COLOR)
# 얼굴 좌표 데이터 값을 뽑기 위한 작업
for i in [annot_A, annot_B, annot_C]:
p1, p2 = (int(i['boxes']['minX']), int(i['boxes']['minY'])), \
(int(i['boxes']['maxX']), int(i['boxes']['maxY']))
# 얼굴 좌표에 맞추어 사각형을 그리는 작업.
cv2.rectangle(img, p1, p2, (0, 255, 0), -1)
break # 장소 데이터 3개가 굳이 필요없다면 break 적용
# 원본 이미지의 해상도가 FHD 기준 해상도를 넘기 때문에 출력하기 위해 내맘대로 사이즈 조정
img = cv2.resize(img, (1000, 800))
count += 1
print(f'[{count}/{len(json_data)}] {filename}') # 몇 번째 파일인지 파일 명과 함께 출력함
cv2.imshow('result', img)
k = cv2.waitKey()
if k == 27: # ESC 누르면 종료
break