
Computer Vision
Definition
인공지능(AI)의 한 분야로, 컴퓨터와 시스템을 통해 디지털 이미지, 비디오 및 기타 시각적 입력에서 의미 있는 정보를 추출한 다음 이러한 정보를 바탕으로 작업을 실행, 추천할 수 있도록 한다.
예를 들어, AI를 통해서 컴퓨터가 생각을 할 수 있고 판단할 수 있다면 컴퓨터 비전을 통해서는 컴퓨터가 보고, 관찰하고 이해할 수 있다.
컴퓨터 비전은 인간의 시각과 메커니즘이 거의 동일하다. 인간의 시력은 사물의 거리, 움직임 등으로 사물을 구분하는데, 이러한 구분 방법을 평생 학습한다.
물론 컴퓨터 비전은 망막, 시신경 등이 아닌 카메라, 데이터 및 알고리즘을 사용하여 훨씬 더 짧은 시간에 수행해야 한다.
사용 예시:
- Image Segmentation: 이미지에서 픽셀 단위로 관심 객체를 추출하는 방법.
- Sementic Segmentation: 이미지에서 픽셀을 물리적 의미 단위로 인식.
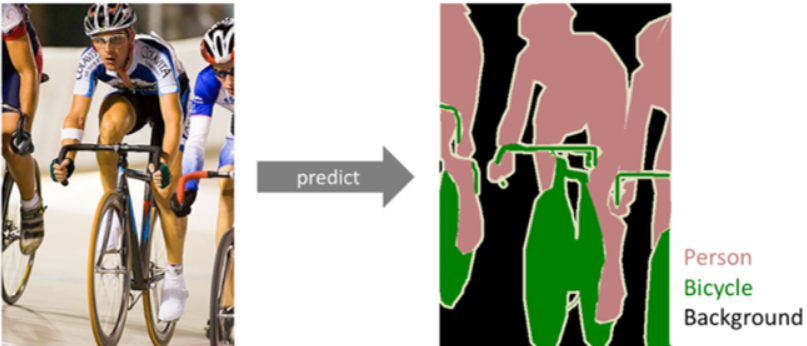
- Instance Segmentation: 시멘틱 방법보다 더 자세하게 분류하는 방법으로, 만약 사람을 인식하면 개인별로 다른 레이블을 할당함.

- Sementic Segmentation: 이미지에서 픽셀을 물리적 의미 단위로 인식.
- Object Detection: 다중 객체에서 각각의 객체에 분류(Classification) + 탐지(Localization) 수행
- Image Classification: 객체의 클래스를 분류하는 방법.
Mechanism
컴퓨터 비전에는 많은 데이터가 필요하며, 차이를 구분하고 궁극적으로 이미지를 인식할 때까지 데이터 분석을 반복적으로 실행한다.
이를 위해 두 가지 필수 기술이 사용되는데, 딥 러닝(Deep Learning)과 CNN(Convolutional Neural Network)이다.
- 딥 러닝: 인간의 두뇌에서 영감을 얻은 방식으로, 데이터를 처리하도록 컴퓨터를 가르치는 인공 지능 방식이다. 딥 러닝 모델은 그림, 텍스트, 사운드 등 데이터의 복잡한 패턴을 인식하여 정확한 통찰력과 예측을 생성할 수 있다. 이 모델을 통해 충분한 데이터가 공급되면 컴퓨터가 데이터를 보고, 이미지를 서로 구별할 수 있도록 스스로 학습한다. 이러한 알고리즘을 사용하면 컴퓨터가 스스로 학습할 수 있다. (AutoML)
딥 러닝 기술은 자율 주행 자동차에서 도로의 차선과 보행자를 감지하는 것과 같이 여러 가지 사용 사례가 있다. - CNN: 합성곱 신경망이라는 뜻이며 이미지 분류에 흔히 쓰인다. 예를 들어 고양이, 강아지, 토끼 등의 사진을 입력했을 때 이를 구분할 수 있도록 하는 용도로 쓰인다. 크게 합성곱층(Convolution Layer)와 풀링층(Pooling Layer)로 구성된다.
전체적인 Flow는 크게 Input -> Feature Learning -> Classification 이렇게 3단계로 구분된다.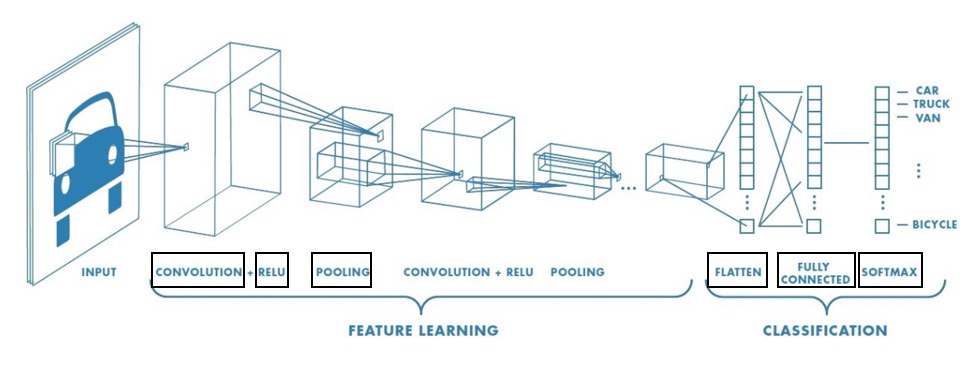
Feature Learning
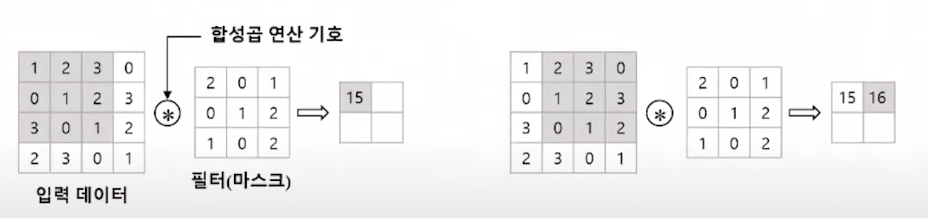
합성곱(Convolution): 2개의 함수 f 와 g가 있을 때, 수학 기호로는 f ∗ g 로 표기한다.
연산 방법은 두 함수 가운데 하나의 함수를 반전(reverse), 전이(shift)시킨 후, 다른 하나의 함수와 곱한 결과를 적분하는 것을 의미한다.
또한 확률 변수 X와 Y가 있을 때, 각각의 확률 밀도 함수를 f와 g라고 하면, X+Y의 확률 밀도 함수는 f ∗ g로 표시할 수 있다.filter=커널: 이미지에서 특정 feature를 추출하기 위한 거름막이라고 생각하면 된다.
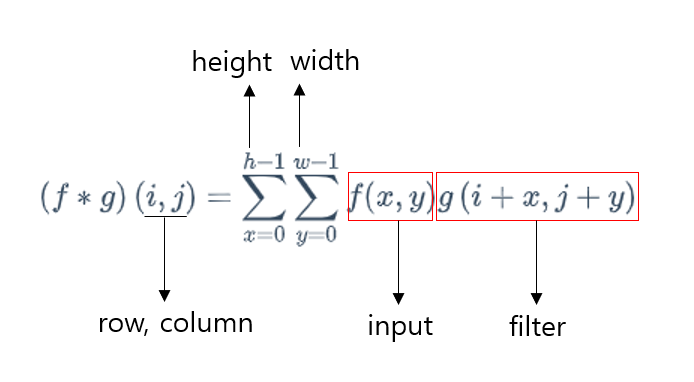
위의 합성곱 수식과 다르게 +x, +y 인 이유는, 합성곱과 유사한 교차상관을 이용하기 때문이다. 사실 CNN은 filter를 학습시키는 것이 주 목적이기에 만약 합성곱을 적용한다면 filter를 반전하는 작업을 거쳐야 하는데 이는 불필요한 작업이다.
ReLU(Rectified Linear Unit): 정류한 선형 유닛에 대한 함수이다. 만약 입력값이 0보다 작으면 0으로 출력하고, 0보다 크면 입력값 그대로 출력한다.
$$
수식: f(x) = x^+ = max(0,x)
$$
이와 같은 함수를 활성화 함수*라고 하는데, 불필요한 데이터는 극소화 시키고 필요한 데이터를 추출하기 위해 필요하다.활성화 함수란 입력 신호의 총 합을 출력 신호로 변환하는 함수이다. 이는 비선형 함수를 사용해야 한다.
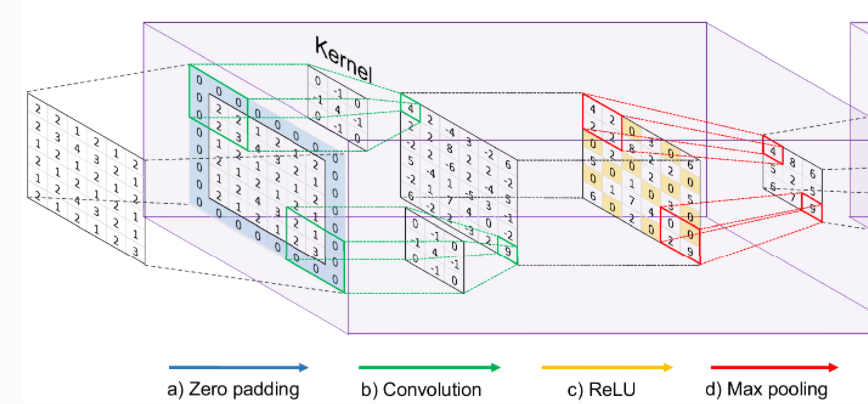
Padding: 합성곱을 진행한 후 feature map의 크기는 입력 크기보다 작아진다. 만약 합성곱 층을 여러 개 쌓았다면 최종적으로 얻은 feature map은 초기 입력보다 매우 작아지는 상태가 된다. 이러한 문제를 해결하기 위해 크기를 동일하게 유지하고 싶다면 패딩(Padding)을 사용한다.
 패딩은 합성곱 연산을 하기 전에 입력의 가장자리에 지정한 개수의 폭만큼 테두리를 추가하는 것을 말한다. 주로 0값을 채우는 제로 패딩(zero-padding)을 사용한다.
패딩은 합성곱 연산을 하기 전에 입력의 가장자리에 지정한 개수의 폭만큼 테두리를 추가하는 것을 말한다. 주로 0값을 채우는 제로 패딩(zero-padding)을 사용한다.
Pooling: 가로, 세로 방향의 공간을 줄이는 연산으로, 일정 영역을 선택하여 특정 값을 하나 가져오는 것이다.
- Max pooling: 아래 그림은 stride=2, 2x2 필터로 Max pooling 진행하였다. 연산을 진행했을 때 feature map이 절반의 크기 다운샘플링된다. 이렇게 필터와 겹치는 영역 안에서 최대값을 추출하는 방식이다.

- Average pooling: Max pooling의 최대값과 다르게, 말 그대로 평균값을 추출하는 방식이다.
- Max pooling: 아래 그림은 stride=2, 2x2 필터로 Max pooling 진행하였다. 연산을 진행했을 때 feature map이 절반의 크기 다운샘플링된다. 이렇게 필터와 겹치는 영역 안에서 최대값을 추출하는 방식이다.
따라서 Feature learning 단계를 정리하면,
a) 합성곱 단계에서 feature map이 지나치게 축소되는 것을 방지하기 위해 zero-padding 추가.
b) 합성곱(≈교차연산) 연산 단계이며, Filter(≈Kernel)를 통해서 feature를 추출.
c) ReLU를 통해 양수값을 제외하고 모두 0으로 치환.
d) Pooling 작업을 통해 각 대상영역의 값을 추출.
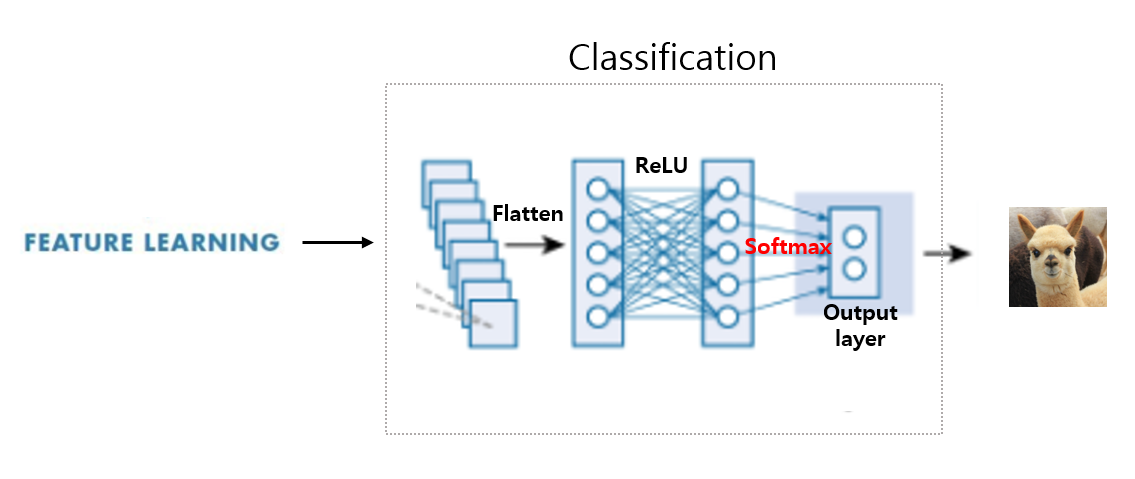
Classification
Flatten: 행렬 평탄화, Flattening이라고도 한다. 이렇게 Flattening된 행렬을 ReLU 함수를 거친 뒤에 Softmax 함수의 input으로 전달한다.
Fully Connectd Layer: Convolution Layer와 Pooling Layer를 통해 추출된 feature map을 분류해야 한다. 따라서 기존 인공 신경망의 구조라고 생각하면 된다.
Softmax 함수: Sigmoid, ReLU 함수와 같은 활성화 함수의 일종이다. Sigmoid 함수가 결과값에 따라 0, 1과 같이 이산 분류하는 함수라면, Softmax는 여러 개의 분류를 가질 수 있는 함수이다.
예를 들어 카테고리가 자동차, 트럭, 비행기, 기차일 때 input 데이터에 대해서
-> 자동차일 확률: 0.7
-> 트럭일 확률: 0.2
-> 비행기일 확률: 0.03
-> 기차일 확률: 0.07
과 같이 표시가 되는데, 이때 모든 카테고리 확률의 합은 1이다.Sigmoid: S자형 곡선을 갖는 수학 함수. 예시로는 로지스틱 함수가 있으며 다음 수식으로 정의됨.
$$
f(x) = \frac{1}{1+\mathrm{e}^{-x}}
$$$$
\sigma(z) = \frac{1}{1+\mathrm{e}^{-z}} = \frac{e^z}{e^z+1}
$$$$
\sigma(z_j) = \frac{\mathrm{e}^{z_j}}{\sum_{i=1}^{K}\mathrm{e}^{z_j}}
$$위의 차례대로 로지스틱 함수, Sigmoid 함수, Softmax 함수이다.
Python에서의 Softmax 함수 사용:
import numpy as np def softmax(x): exps = np.exp(x) softmax_vals = exps / np.sum(exps) return softmax_vals input_vector = np.array([2, 1, -1]) output = softmax(input_vector) print(output) # 결과값 # [0.70538451 0.25949646 0.03511903]
따라서 Classification 단계를 정리하자면,
Flatterning 되어 평탄화된 행렬을 ReLU나 Softmax 함수를 거쳐 0 ~ 1사이의 확률값 형태로 output을 얻는 단계을 의미한다.
CNN 알고리즘의 종류
- VGGNet(Very Deep Convolution Network): 16개 또는 19개 층으로 구성된 모델을 의미한다. 필터의 크기는 3 x 3를 사용하는데, 이는 5 x 5 필터로 1번 합성곱을 하는 것과 3 x 3 필터로 2번 합성곱을 하는 것의 동일한 사이즈의 feature map을 산출한다. 그리고 3 x 3 필터로 3번 합성곱과 7 x 7 필터로 1번 합성곱과도 같다.
그러면 3 x 3 필터로 하는 것이 더 나은 점은 가중치(parameter)가 적다는 것이다. 가중치가 적다는 것은 훈련시켜야 할 갯수가 적어진다는 뜻으로, 따라서 학습의 속도가 빨라진다.
작은 필터를 사용함으로 ReLU와 같은 활성화 함수가 들어갈 수 있는 곳이 많아진다. 이런 함수를 적용시켜 비선형성을 가지게 하여 CNN에서 레이어를 쌓는다는 의미이며 레이어의 깊이가 깊어질 수록 학습의 효과를 증폭시키게 되는 것이다.
Deep Learning 용어 정리
- CNN(Convolution Neural Network): 합성곱 신경망. 주로 이미지 식별 용도로 사용.
- R-CNN(Regions with CNN features): 선택한 사각형 영역을 CNN과 결합하여 사용. 성공적인 객체 탐지 초기 모델 중 하나지만 복잡하고, 상당한 시간이 소요된다.
- RNN(Recurrent Neural Network): 순환 신경망. 주로 텍스트 분류에 사용. 시간이 지나도 정보가 지속될 수 있는 피드백 루프가 있어 메모리가 필요한 작업에 용이하다. 따라서 시간적 또는 순차적 데이터를 처리하는데 적합하다. 주로 음성 인식, 시계열 예측 등 작업에 사용된다.
RNN에서는 현재 단계의 출력이 다음 단계의 입력이 되는 형태이다. - GAN(Generative Adversarial Networks): 생성적 적대 신경망. 새로운 데이터를 생성하며, 진짜와 가짜를 판별하기 위한 학습 진행.
'Development > Computer Vision' 카테고리의 다른 글
| Object Detecting, 객체 탐지 정리 [1] (0) | 2024.02.08 |
|---|